- Published on
搞懂 AI 智能体,这 10 个概念就够了
- Authors

- Name
- 俞凡
从 MCP 插件系统到运行时编排,本文用可视化方式讲解了构建生产级 AI 智能体必须掌握的 10 个核心概念,帮你把 AI Demo 变成真正可靠的生产系统。原文:10 AI Agent Concepts Every Developer Must Master in 2026 ( With Visual Explanation))
你肯定遇到过这种情况:新建一个 AI 智能体项目,测试时一切正常,然后用户让它"查看我的日历,预订下周去奥斯汀最便宜的航班",结果它直接……僵住了?更糟的是,它因为误读工具输出,订了一张去澳大利亚的机票?
我经历过。三个月前,看着智能体无限循环,一直尝试抓取一个需要登录的页面。它在我发现并终止前,已经烧了 47 美元的 API 调用费用。
AI 智能体不只是选择合适的 LLM 或编写巧妙的提示词,核心在于理解基础系统架构,让智能体在无人监督的情况下完成实际工作并保持可靠。
能惊艳团队的演示,和每周节省 10 小时的生产级智能体,差别就在于这 10 个概念。
本文将分享那些在构建第一个智能体之前需要知道的真相,这些都是构建 AI 系统时真正重要的东西。
1. MCP:通用插件系统
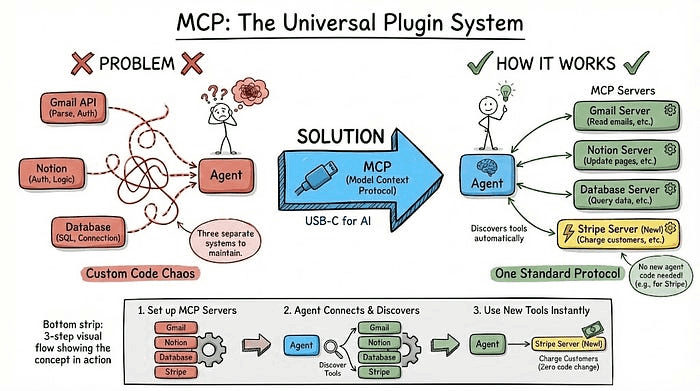
你希望智能体读取 Gmail、更新 Notion 并查询数据库。通常情况下,需要为每个服务编写自定义集成代码:解析 Gmail API、梳理 Notion 认证、编写 SQL 连接逻辑,三个独立系统就需要维护三个不同的代码库。
MCP(模型上下文协议)通过创建一种标准让智能体与任意工具交互,解决了这个问题。它就像 AI 领域的 USB 接口。你不需要为手机上的每个应用配备不同的接口。这里的理念是一样的。
搭建 MCP 服务器,每个服务器暴露工具,并清晰描述它们的功能和所需输入。
智能体连接到这些服务器,自动发现可用工具。想添加 Stripe 支付?只需启动 Stripe 的 MCP 服务器,智能体立即就能知道如何向客户收费,而无需修改任何智能体代码。
示例: 运行一个暴露"send_email"函数的 MCP 服务器,服务器描述为"向指定地址发送带主题和正文的电子邮件",智能体可以在工具列表中看到。当用户说"把报告发给 john@company.com"时,智能体使用正确的参数调用该函数。下次你添加一个"search_github"服务器,智能体也能发现并开始使用,而无需修改代码。
2. 推理循环(The Reasoning Loop):思考、行动、观察,重复
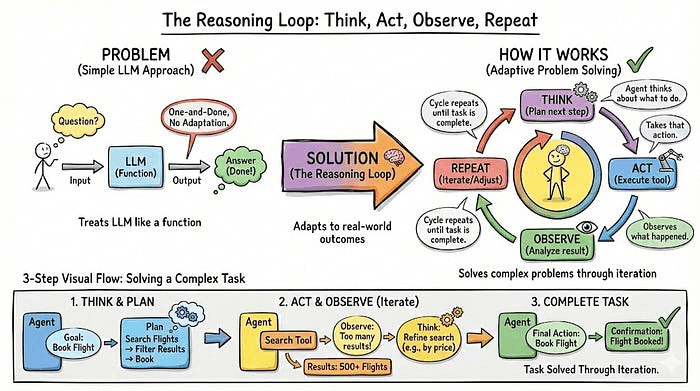
大多数开发者把 LLM 当作简单函数:问问题,获得答案,结束。但真实的任务不是一次性完成的,需要根据发生的情况进行调整。
推理循环是智能体解决问题的实际方式。
智能体思考该做什么,执行该行动,观察发生了什么,然后再次思考该方法是否有效,下一步该尝试什么。这个循环重复直到任务完成。
示例: 让智能体查找竞争对手的定价。它想:"我去他们网站看看",访问网站,得到 404 错误。它观察到:"页面不存在"。再次思考:"那我试试主页",找到主页,定位到定价链接,跟进并提取数据。每一步都建立在前一个结果的基础上。智能体在第一种方法失败时进行了调整,而不是直接崩溃。
3. 记忆(Memory):短期和长期上下文
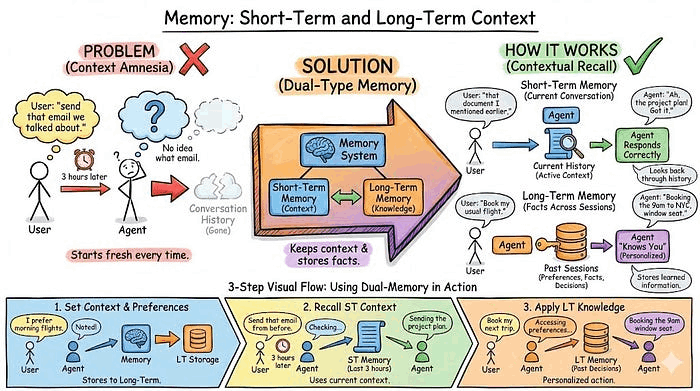
你的智能体和用户进行了一次对话。三小时后,用户说"发送我们刚才谈到的那封邮件",智能体完全不知道说的是哪封邮件,因为对话历史已经丢失了。
- 短期记忆将当前对话保留在上下文中。当你说"我刚才提到的那份文档"时,智能体可以回顾对话历史,找到你指的是哪份文档。
- 长期记忆跨会话存储事实,包括用户偏好、过去决策、学到的信息。这会让智能体感觉它真的认识你,而不是每次都从头开始。
示例: 用户说"我更喜欢上午 10 点前的会议"。你将其存储在绑定用户 ID 的长期记忆中。下周,用户说"安排一个和 Sarah 的会议"。智能体检查记忆,看到偏好上午,因此建议上午 9 点时段。没有记忆的话,它会随机推荐时间,用户每次都得重复说一遍偏好。
4. 护栏(Guardrails):行动前验证
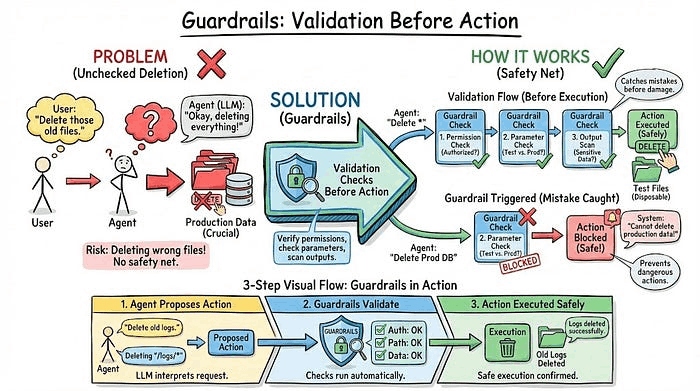
智能体想要删除文件,LLM 确信这是用户要求的。但如果它错了怎么办?如果它要删除的是生产数据而不是测试文件怎么办?
护栏是在任何行动执行前运行的验证检查。它们验证权限、检查参数是否合理,并扫描输出中的敏感数据。把它们看作在错误造成损害之前捕捉错误的安全网。
示例: 用户说"清理旧的测试数据"。你的智能体将其解释为删除 50,000 条数据库记录。执行前,护栏检查:这个用户删除权限吗?对于"旧测试数据"来说,50,000 条记录合理吗?护栏将其标记为可疑并要求用户确认。结果用户本意是删除 50 条记录,不是 50,000 条,从而避免了一场灾难。
5. 工具发现(Tool Discovery):自动学习新能力
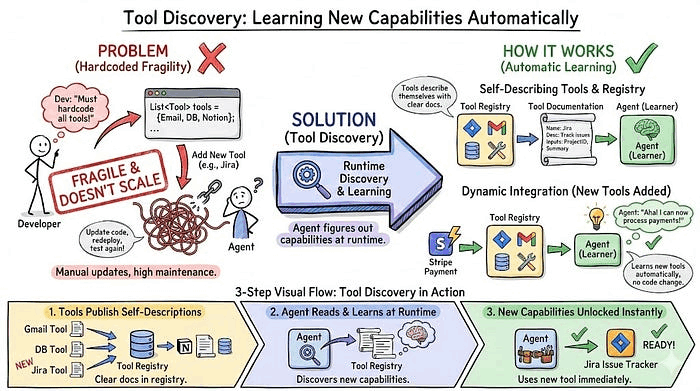
你可以把工具列表硬编码到智能体中,但如果下个月你想添加 Jira 集成,就需要更新智能体代码、重新部署并再次测试所有内容。这很脆弱,也无法扩展。
工具发现意味着智能体在运行时就能弄清楚它能做什么。工具通过清晰的文档描述自身,智能体读取这些描述,添加新工具后自动学习如何使用。
示例: 你的智能体已经在生产环境运行。你通过部署 MCP 服务器添加了新的日历集成,该服务器暴露"create_event"和"list_events"函数并附带描述。下次有人要求"安排团队会议",智能体就可以在可用列表中看到日历工具,读取它们的功能并正确使用。不需要修改智能体代码,它自己能够发现新能力。
6. 错误恢复(Error Recovery):优雅失败
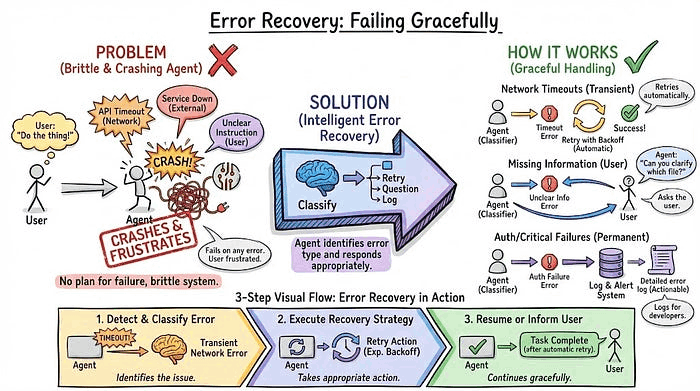
API 会超时,服务会宕机,用户会给出不清晰的指令。智能体一定会遇到错误,问题在于它会崩溃还是智能处理。
错误恢复在于对问题分类并做出适当响应:网络超时时尝试重试,缺少信息时向用户提问,认证失败时记录清晰日志。
示例: 智能尝试发送电子邮件,SMTP 服务器超时。它没有崩溃,而是等待 2 秒后重试。还是失败,再等 4 秒重试,第三次成功了。用户根本不知道出了问题。另一种情况:超时一直发生。三次尝试后,智能体告诉用户:"邮件服务现在宕机了。我已经保存了你的草稿,10 分钟后重试。"清晰沟通发生了什么,以及正在采取什么措施。
7. 人类参与(Human in the Loop):知道何时该提问
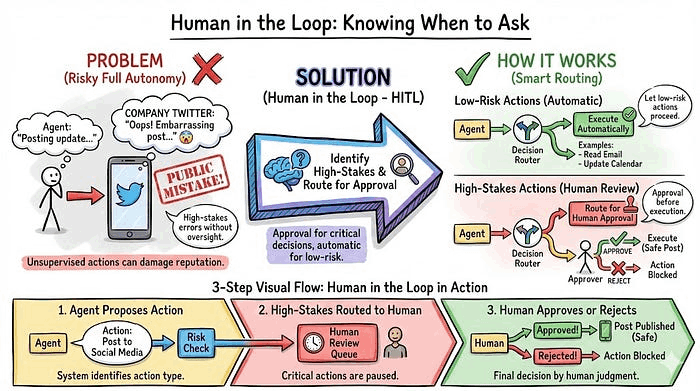
完全自主听起来不错,直到智能体在公司 Twitter 账号发布了尴尬内容。有些决策在执行前需要人类判断。
人类参与不是对每个动作微观管理,而在于识别高风险决策并路由给人工批准,同时让低风险行动自动执行。
示例: 你的社交媒体智能体自动起草并发布帖子,日常更新运行得很好。但当它起草对客户产品缺陷投诉的回复时,会暂停并发送通知:"我起草了这篇回复,应该发布吗?"你审核后做了小修改并批准发布,智能体进行了发布。高风险行动得到审核,低风险行动自动完成,不需要一直盯着就能保持控制。
8. 上下文工程(Context Engineering):提供正确信息
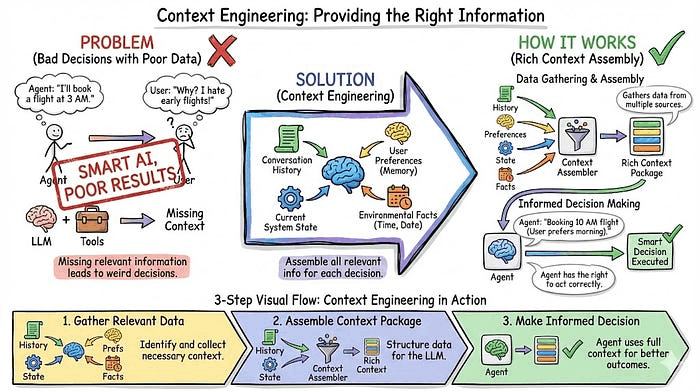
你拥有最聪明的 LLM 和完美的工具,但智能体却做出了奇怪的决策。为什么?因为它没有正确的信息可用。
上下文工程就是为每个决策收集相关信息。不只是对话历史,还包括来自记忆的用户偏好、当前系统状态,以及时间日期等环境事实。
示例: 用户问"我应该重新安排明天的户外会议吗?"坏上下文:只有问题本身。好上下文:问题、明天天气预报(70% 降雨概率)、用户日历显示的户外团建活动、用户过去避免雨天延误的偏好,以及可用的室内备用会议室。有了完整上下文,智能体建议搬到 B 会议厅并给出可靠推理。没有上下文,智能体只能瞎猜。
9. 状态管理(State Management):跟踪复杂任务
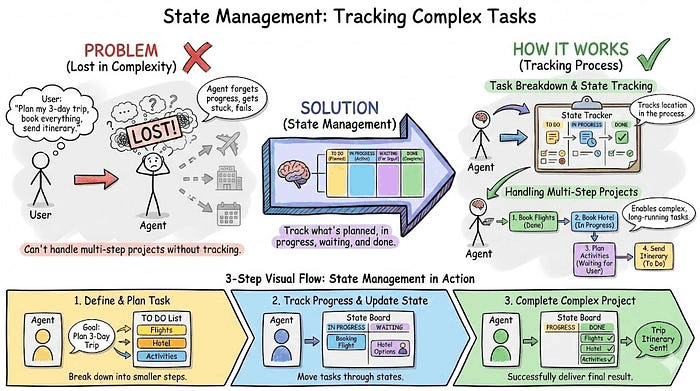
用户不会只问简单问题,而是会执行耗时数小时甚至数天的多步骤项目,而智能体需要跟踪当前处于流程的哪个位置。
状态管理用于跟踪计划了什么、什么在进行中、什么在等待输入、什么已经完成的方式。没有它,智能体无法处理任何比单次查询更复杂的任务。
示例: 用户说"研究我们的前 5 名竞争对手并创建对比表格"。智能体将其拆分为子任务:第一步:识别竞争对手(进行中),第二步:研究每个竞争对手(计划中,等待第一步完成),第三步:创建表格(计划中,等待第二步完成)。智能体逐步处理,跟踪每个任务的状态。如果需要用户输入("哪些指标最重要?"),它会将该子任务标记为等待,提问,然后继续处理其他事情。当你回答后,它会从打断的地方继续。没有状态跟踪,智能体会失去目标并重新开始。
10. 运行时编排(Runtime Orchestration):管理执行环境
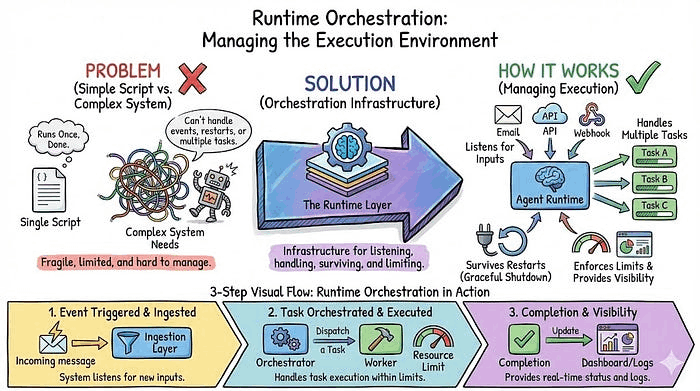
智能体不只是运行一次的脚本,而是一个需要响应事件、处理多个任务、在重启后恢复,并在资源限制内运行的系统。
运行时编排是基础设施层,负责管理智能体如何监听不同来源的输入、处理优雅关闭、提供对当前行为的可见性,以及强制执行限制防止失控。
示例: 你的智能体监听三个输入来源:Slack 消息、定时任务和 webhook 回调。事件队列将每个请求路由到正确的处理程序。用户发送紧急 Slack 消息,立即得到响应。定时报告在后台运行。当你部署新版本时,关闭处理程序保存所有进行中任务的状态。新版本启动,加载这些状态并从断点继续。同时,资源限制确保任何单个任务运行不超过 5 分钟或发起超过 50 次 API 调用。分布式追踪能在出问题时准确显示发生了什么。
何时使用每个概念:决策指南
从零开始? 从 MCP 和工具发现开始。构建基础,让添加新能力变得容易。不要硬编码集成,后面会后悔的。
测试正常,生产失败? 添加护栏和错误恢复。执行前验证,瞬态故障重试。生产环境包含所有测试遗漏的边缘情况。
智能体忘记事情或看起来很笨? 实现记忆。短期记忆用于对话,长期记忆用于持久事实。上下文工程确保你在决策时提供正确信息。
任务卡住或耗时太长? 检查推理循环和状态管理。将复杂请求拆分为可跟踪的子任务。让智能体在计划不如变化时能够适应。
担心安全性? 加倍关注护栏和人类参与。从保守开始,当你对智能体处理能力建立信任后再扩大自主权。
提示词没问题但决策错误? 修复上下文工程。确保智能体看到相关的用户偏好、系统状态和环境事实。记录提供的上下文,方便调试。
部署和监控问题? 专注运行时编排。事件处理、优雅关闭、可观测性、资源限制。你无法修复看不到的问题。
需要快速集成大量服务? 使用 MCP 服务器。一个协议支持无限工具。不用再为每个新服务重写集成代码。
API credits 烧得太快? 添加资源限制。限制每个任务的执行时间和 API 调用次数。快速失败,而不是掏空预算。
用户不信任? 将高风险决策的人工审批和其他所有情况的可靠错误恢复相结合。透明度建立信任。展示智能体在做什么,为什么这么做。
参考表:实现检查清单
MCP 设置: 安装 SDK。创建定义工具为函数的服务器文件。为每个工具编写清晰描述,解释功能和使用时机。包含参数类型。将智能体连接到服务器。测试工具能被自动发现。
推理循环: 构建一个运行直到任务完成的 while 循环。LLM 决定下一步行动。执行该行动。将结果反馈给 LLM。让它观察并决定下一步。重复。记录每次迭代方便调试。
记忆系统: 创建对话历史(短期)数据库表。另一个表存放用户偏好和学到的事实(长期)。组装上下文时查询记忆。添加嵌入语义搜索提高召回率。定期清理旧对话。
护栏: 在每个行动前运行验证函数。检查用户权限。验证参数合理。扫描输出中的敏感数据。如果检查失败,阻止并记录。返回清晰错误解释原因。
工具发现: 注册表在运行时列出所有可用工具。每个工具都有名称、描述和参数模式。在系统提示中将注册表传递给智能体。添加新工具后自动出现。智能体无需修改代码就能学会使用。
错误恢复: 将工具调用包装在错误处理中。分类为瞬态错误、用户可修复错误或致命错误。延迟重试瞬态错误(2s、4s、8s)。向用户询问缺失信息。清晰记录并解释致命错误。主方法失败时有后备选项。
人工批准: 按置信度和风险对决策打分。高风险或低置信度需要批准。低风险自动进行。异步实现让智能体在等待时可以处理其他任务。记录所有批准。根据模式调整阈值。
上下文组装: 在每个决策前收集信息的函数。最近对话消息。来自记忆的相关用户偏好。当前时间和时区。可用工具。相关过去交互的语义搜索。按相关性过滤。记录组装好的上下文。
状态跟踪: 定义任务状态(计划中、进行中、等待、阻塞、已完成、失败)。将当前状态存储在数据库中。分别跟踪子任务。积累结果时保存。状态变化时更新数据库。重启时加载以恢复任务。
运行时基础设施: 事件队列监听多个来源。路由到同步或异步处理程序。终止时关闭处理程序保存状态。分布式追踪跟踪决策和工具调用。对每个任务的时间和 API 调用进行资源限制。监控错误率和持续时间。异常时告警。
总结
选一个概念,今天就来构建点小东西。
如果厌倦了重写集成,从 MCP 开始。如果智能体总是忘记上下文,添加记忆。如果担心可能出问题,实现护栏。
不要试图一下子构建所有东西。掌握一个,发布,然后继续下一个。